Research team
Faculty
Dr. Vasileios Lampos, Associate Professor
Research staff
Dr. Magnus Ross, Research Fellow
David Guzman, Software Engineer (collaborator)
PhD students
Yuxuan Shu
George Drayson
Zahra Solatidehkordi
Jinyu Li
Ruoqing Yin (tertiary supervisor)
Alumni
Dr. Michael Morris
Research highlights

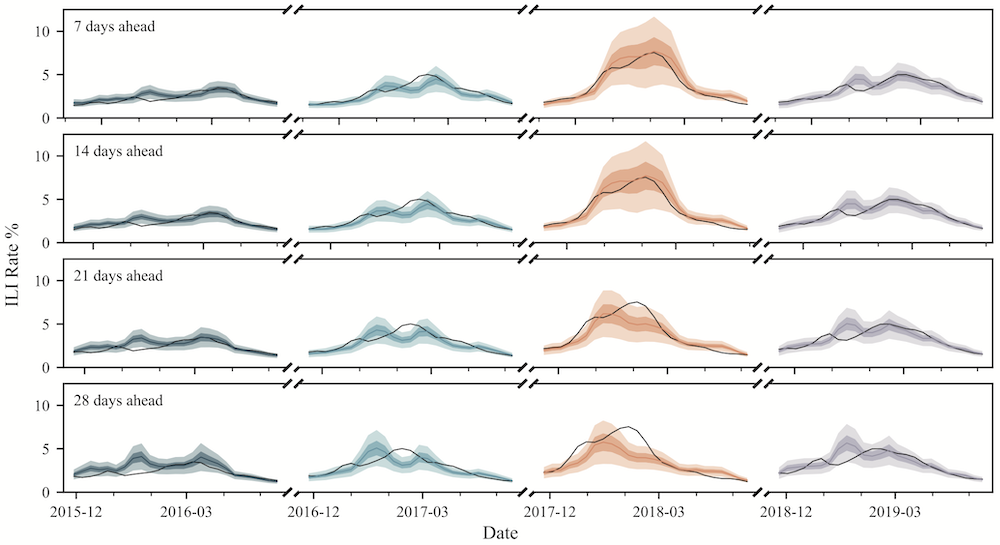




Time series forecasting with DeformTime (TMLR)
DeformTime is a neural network architecture that attempts to capture correlated temporal patterns from the input space and, hence, improve forecasting accuracy. It deploys two core operations performed by deformable attention blocks (DABs): learning dependencies across variables from different time steps (variable DAB), and preserving temporal dependencies in data from previous time steps (temporal DAB). Experiments across 6 multivariate time series forecasting data sets demonstrate that DeformTime improves accuracy against previous competitive methods by reducing the mean absolute error by 10% on average. Notably, performance gains remain consistent across longer forecasting horizons.
DeformTime is a neural network architecture that attempts to capture correlated temporal patterns from the input space and, hence, improve forecasting accuracy. It deploys two core operations performed by deformable attention blocks (DABs): learning dependencies across variables from different time steps (variable DAB), and preserving temporal dependencies in data from previous time steps (temporal DAB). Experiments across 6 multivariate time series forecasting data sets demonstrate that DeformTime improves accuracy against previous competitive methods by reducing the mean absolute error by 10% on average. Notably, performance gains remain consistent across longer forecasting horizons.
Forecasting flu rates and associated uncertainty using online search activity (PLOS Comp. Biol. 2023)
We propose neural network architectures for forecasting influenza-like illness rates and associated uncertainty bounds by incorporating Web search activity trends. We obtain very competitive accuracy that significantly improves upon established approaches.
We propose neural network architectures for forecasting influenza-like illness rates and associated uncertainty bounds by incorporating Web search activity trends. We obtain very competitive accuracy that significantly improves upon established approaches.
Estimating COVID-19 prevalence from web search activity (npj Digit. Med. 2021, Nat. Med. 2020)
We propose a methodology for estimating a COVID-19 prevalence indicator using web search activity. Our model accounts for potential biases in search trends influenced by the news, and shows results for 8 countries (npj Digit. Med. 2021). Daily estimates for the UK and England are presented on our website. These estimates are used by UKHSA as part of their syndromic surveillance systems. This work has been covered in a press release by UCL. We have also authored a survey on how digital technologies have been used in responding to the COVID-19 pandemic (Nat. Med. 2020).
We propose a methodology for estimating a COVID-19 prevalence indicator using web search activity. Our model accounts for potential biases in search trends influenced by the news, and shows results for 8 countries (npj Digit. Med. 2021). Daily estimates for the UK and England are presented on our website. These estimates are used by UKHSA as part of their syndromic surveillance systems. This work has been covered in a press release by UCL. We have also authored a survey on how digital technologies have been used in responding to the COVID-19 pandemic (Nat. Med. 2020).
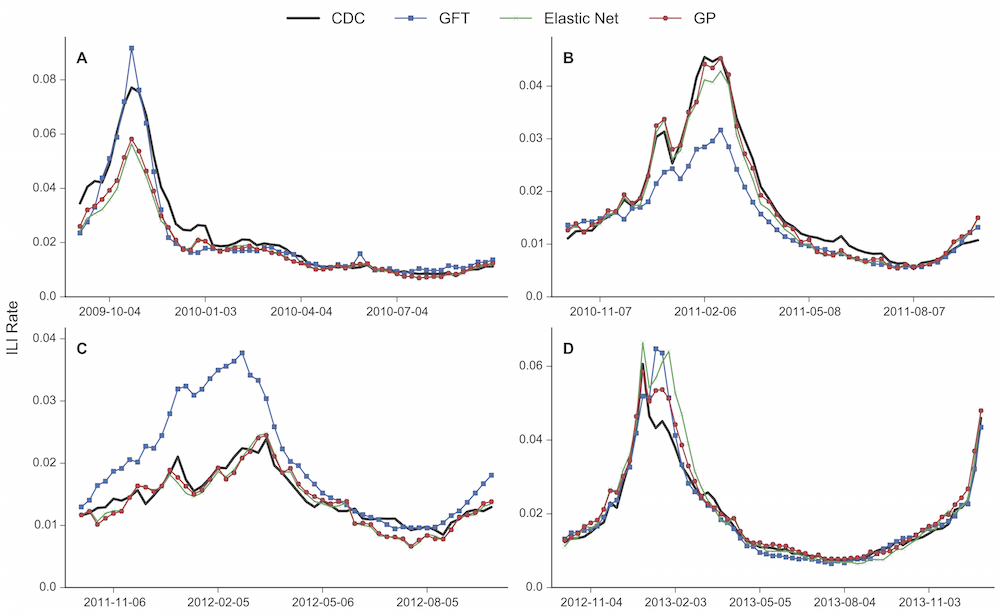
Estimating flu rates from web search activity (Sci. Rep. 2015, WWW '17, WWW '18, WWW '19)
Previous attempts to model flu rates from search query frequency time series (such as Google Flu Trends) ended up with producing significant errors (see, for example, this article). Our modelling approaches provide more accurate estimates by capturing nonlinearities in the feature space (Sci. Rep. 2015) and improving feature selection (WWW '17). We have also proposed multi-task learning frameworks for obtaining accurate models when training data is limited (WWW '18). We have proposed a transfer learning framework for adapting a flu prevalence model from one country to another that has no access to historical health surveillance data (WWW '19). An online tool, titled Flu Detector, uses our methods to estimate and display flu rates for England on a daily basis. Flu Detector's estimates are included in UKHSA's weekly syndromic surveillance reports.
Previous attempts to model flu rates from search query frequency time series (such as Google Flu Trends) ended up with producing significant errors (see, for example, this article). Our modelling approaches provide more accurate estimates by capturing nonlinearities in the feature space (Sci. Rep. 2015) and improving feature selection (WWW '17). We have also proposed multi-task learning frameworks for obtaining accurate models when training data is limited (WWW '18). We have proposed a transfer learning framework for adapting a flu prevalence model from one country to another that has no access to historical health surveillance data (WWW '19). An online tool, titled Flu Detector, uses our methods to estimate and display flu rates for England on a daily basis. Flu Detector's estimates are included in UKHSA's weekly syndromic surveillance reports.
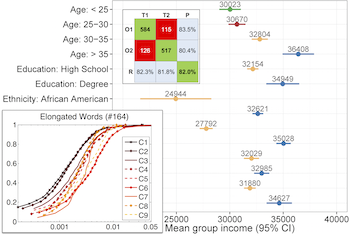
Inferring characteristics of social media users (EACL '14, ACL '15, PLOS ONE 2015, ECIR '16)
We show that it is possible to infer the occupational class, income, socioeconomic status and impact of Twitter users from their tweets (n-grams and topics) as well as a number of platform-related activity patterns. A blog post summarises parts of this work in an informal fashion.
We show that it is possible to infer the occupational class, income, socioeconomic status and impact of Twitter users from their tweets (n-grams and topics) as well as a number of platform-related activity patterns. A blog post summarises parts of this work in an informal fashion.
Assessing the impact of a health intervention using social media and web search (Data Min. Knowl. Discov. 2015, JMIR 2017)
We introduce a framework for evaluating the impact of a targeted intervention, such as a vaccination campaign against an infectious disease, through a statistical analysis of social media and web search activity trends. Our case study focuses on the influenza vaccination program that was launched in England during the 2013/14 and 2014/15 flu seasons.
We introduce a framework for evaluating the impact of a targeted intervention, such as a vaccination campaign against an infectious disease, through a statistical analysis of social media and web search activity trends. Our case study focuses on the influenza vaccination program that was launched in England during the 2013/14 and 2014/15 flu seasons.
Detecting events using social media (CIP '10, ECML PKDD '10, ACM TIST 2012)
This research presents the first set of experiments showing that social media content can be used to track the prevalence of an infectious disease, such as influnza-like-illness (ILI). To achieve that we collected geolocated tweets from 54 UK cities, used them in a regularised regression model which was trained and evaluated against ILI rates from the Health Protection Agency (then renamed to PHE, and now known as UKHSA). Flu Detector is a demonstration that used (now moved here using a different/revised approach) the content of Twitter for nowcasting the level of ILI in several UK regions on a daily basis. These findings led to the development of a more generic statistical framework for supervised event mining and quantification from social media, which included the modelling of rainfall rates as a benchmark.
This research presents the first set of experiments showing that social media content can be used to track the prevalence of an infectious disease, such as influnza-like-illness (ILI). To achieve that we collected geolocated tweets from 54 UK cities, used them in a regularised regression model which was trained and evaluated against ILI rates from the Health Protection Agency (then renamed to PHE, and now known as UKHSA). Flu Detector is a demonstration that used (now moved here using a different/revised approach) the content of Twitter for nowcasting the level of ILI in several UK regions on a daily basis. These findings led to the development of a more generic statistical framework for supervised event mining and quantification from social media, which included the modelling of rainfall rates as a benchmark.